ექსელში მუშაობისას ძალიან ეფექტურია წინასწარ განსაზღვრული დიაპაზონიდან მოცემულ სიასთან მუშაობა Data Validation-სთვის, დიაგრამებისთვის და ა.შ. თუმცა ყოველდღიური პრაქტიკული ამოცანები მოითხოვენ რომ ასეთი სიები მაქსიმალურად მოქნილნი იყვნენ. მაგალითად რაღაც პოზიცია შეიძლება არ იყოს უკვე აქტუალური და უნდა წაიშალოს ან პირიქით სიას დაემატოს პროდუქტების ახალი დასახელებები და შესაბამისად ერთ სიაში ამ ცვლილების ასახვით ისინი უნდა გავრცელდნენ მთელ ფაილზე. ასეთ სიებს ხოლმე დინამიურად განსაზღვრულს უწოდებენ.
დინამიურად განსაზღვრული სიის ფორმირებისთვის მრავალი მეთოდი არსებობს, მაგრამ ჩვენ დღეს ვისაუბრებთ ერთ-ერთ ყველაზე მარტივზე – ფუნქცია INDEX-ის გამოყენებით.
ყველაზე მარტივი დიაპაზონი შეიძლება გაკეთდეს სვეტში მოცემული მონაცემებისგან:

ვინაიდან არ გვინდა, რომ სათაურიც მოხვდეს სიაში მის ფორმირებას დავიწყებთ A2 უჯრიდან. სტანდარტულ სიტუაციაში სიის დიაპაზონი იქნებოდა $A$1:$A$6. მაგრამ რადგანაც გვინდა რომ ეს სია მაქსიმალურად მოქნილი იყოს და ასახავდეს მასში ახალი დასახელებების დამატებას ან ძველების წაშლას გამოვიყენებთ მსგავსი ტიპის ფორმულას:
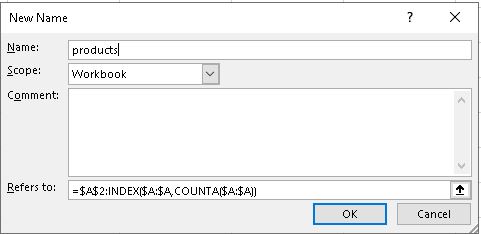
=$A$2:INDEX($A:$A,COUNTA($A:$A))
აღნიშნული ფორმულა უნდა ჩავწეროთ დიალოგურ ფანჯარაში, რომელსაც გამოვიძახებთ Formulas თაბიდან Define Names ბრძანებით.

მოდით გავარჩიოთ, როგორ მიიღწევა ასეთი შედეგი:
ჩვენ ფორმულა იწყება A2 უჯრით და შემდეგ მოდის დიაპაზონის აღმნიშვნელი : ანუ ნათელია, რომ დიაპაზონი იწყება A სვეტის 2 უჯრიდან, დიაპაზონის სიმბოლოს მერე მოდის ფუნქცია INDEX, რომელიც თავის მხრივ რაღაც მონაცემებს იღებს მეორე ფუნქციიდან COUNTA-დან. ამიტომ უფრო ყურადღებით შევხედოთ ჩვენი ფორმულის ამ კონსტრუქციას:
INDEX($A:$A,COUNTA($A:$A))
ეს კონსტრუქცია განსაზღვრავს თუ რომელი იქნება A2 დაწყებული დიაპაზონის ბოლო უჯრა: კონკრეტულად კი COUNTA ადგენს რომელი არის ბოლო შევსებული (არა ცარიელი უჯრა) და ამ ინფორმაციას გადასცემს ფუნქცია ინდექსს, რომელიც უკვე განსაზღვრავს დიაპაზონის ბოლო უჯრას.
მსგავსი მიდგომით შესაძლებელია ასევე დინამიური დიაპაზონის ფორმირება როგორც სვეტების ისე სტრიქონების მეშვეობით. (მართალია ასეთი დინამიური დიაპაზონი Data Validation-ისთვის შეიძლება აღარ იყოს გამოსადეგი, მაგრამ მისი გამოყენება შეიძლება მაგალითად დიაგრამებში, ან რაიმე ფორმულებში)
=$A$1:INDEX($1:$1048576,COUNTA($A:$A),COUNTA($1:$1))
აღნიშნულ შემთხვევაში ინდექსი მოიცავს ექსელის გვერდის ყველა უჯრას დაწყებული 1დან დამთავრებული 1048576 (უფრო გადაზღვევის მიზნით, არა მგონია ოდესმე მთლიანად შეავსოთ ექსელის გვერდი), ხოლო COUNTA „აკონტროლებს“ როგორც სვეტებს, ისე სტრიქონებს.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Leave A Comment